
Article

Claude 3.5 Sonnet vs. GPT-4.0: Who Wins the AI Showdown?
In the perpetual race towards AI supremacy, Anthropic has unveiled its latest innovation: Claude 3.5 Sonnet. Positioned as a formidable contender against industry giants like OpenAI’s GPT-4.0 and Google’s Gemini series, Claude 3.5 Sonnet introduces significant advancements in AI capabilities. For tech enthusiasts and industry professionals alike, understanding the nuances of this new model is pivotal in navigating the evolving landscape of artificial intelligence.
Key technological advancements in the AI model
Anthropic’s Claude 3.5 Sonnet represents a leap forward in AI sophistication. Claude 3.5 Sonnet is engineered to excel in various tasks, leveraging its expanded 200K token context window to achieve unparalleled levels of language understanding and processing. This capability not only enhances the model’s ability to generate coherent and contextually accurate responses but also facilitates complex reasoning tasks such as writing and translating code, interpreting complex multistep workflows, and accurately transcribing data from visual sources like charts and graphs.
[Image Source: Textcortex]
One of the standout features of Claude 3.5 Sonnet is its remarkable speed, reportedly twice as fast as its predecessor. This enhancement is particularly significant in dynamic environments where rapid data processing and response times are critical, such as financial trading platforms and customer support systems.
Anthropic has integrated Claude 3.5 Sonnet with enhanced vision capabilities, enabling it to interpret and extract meaningful insights from visual data sources with unprecedented accuracy. This includes the ability to transcribe text from images, a feature poised to revolutionize applications requiring detailed image analysis and content extraction.
Performance evaluation of Clause 3.5 Sonnet model vs. GPT-4o
In a recent head-to-head comparison of two advanced AI models, Claude 3.5 and GPT-4.0, we explored their capabilities in code generation, logical reasoning, and mathematical problem-solving. A comparative evaluation against OpenAI’s GPT-4.0 reveals distinctive strengths and considerations:
1. Code generation: From command line to GUI
When tasked with generating Python code to build a basic web scraper, both Claude 3.5 and GPT-4.0 produced functional command-line scripts. Claude 3.5 stood out by including advanced features such as error handling and the ability to set custom headers for HTTP requests, which GPT-4o did not offer. Moreover, Claude’s code was more streamlined and efficient, avoiding unnecessary libraries that GPT-4o sometimes included.
Shifting the focus to generating a GUI application for the same web scraper, the prompt was refined to “write a web scraper with a graphical user interface.” Claude 3.5 responded with a fully functional desktop application featuring a user-friendly interface built with Tkinter, allowing users to input URLs and view results in real-time. GPT-4.0, however, continued to generate a command-line interface, missing the mark on creating an accessible graphical experience.
2. Logical reasoning: Tackling technical scenarios
For the first logical puzzle, we asked the models to solve a technical hierarchy problem: “A software developer reports to a team lead. The team lead reports to a project manager, and the project manager reports to a department head. The department head is the only direct report of the CTO. What is the relationship between the software developer and the CTO?” Both models navigated the hierarchical structure correctly, concluding that the software developer is indirectly connected to the CTO through the reporting chain, resulting in a tie.
In a second puzzle involving technology terms, we asked, “Which of the following tech terms is least related to the others: API, SDK, Algorithm, or Framework?” Claude 3.5 reasoned that “Algorithm” was the outlier, as it is a conceptual method rather than a concrete tool or set of tools used in software development, unlike the other terms, which are more directly associated with software development kits and tools. GPT-4.0identified “API” as different, noting that it is a specific interface for interacting with software rather than a broader toolkit or methodology. The differing interpretations show that the task’s ambiguity can lead to varied insights.
3. Mathematical reasoning: Algorithmic efficiency
Our final challenge involved a mathematical problem related to algorithmic efficiency: “A data processing algorithm operates with a time complexity of O(n^2). If the size of the dataset is increased from 10,000 to 20,000, by what factor does the execution time increase?”
GPT-4o excelled in this test, accurately calculating that the execution time would increase by a factor of four, reflecting the quadratic time complexity. Claude 3.5, however, miscalculated the factor as eight, demonstrating a lapse in understanding the impact of time complexity on execution time.
Pricing breakdown: Claude 3.5 Sonnet vs. GPT-4.0
As AI models like Claude 3.5 Sonnet and GPT-4o become integral to various applications, understanding their pricing structures is crucial for businesses and individual users alike. Both Claude 3.5 Sonnet and GPT-4.0 offer competitive pricing for their premium features and API usage. While the base subscription costs for Claude Pro and ChatGPT Plus are identical at $20 per month, the differences emerge in API pricing:
- Claude 3.5 Sonnet API: $3 per million tokens input and $15 per million tokens output.
- GPT-4o API: $5 per million tokens input and $15 per million tokens output.
Claude 3.5 Sonnet presents a more cost-effective option for token input, making it potentially more attractive for high-volume input scenarios. GPT-4o, however, maintains a uniform output fee, potentially simplifying budgeting for output-heavy tasks.
[Image Source: Textcortex]
Claude vs. GPT-4: The final verdict
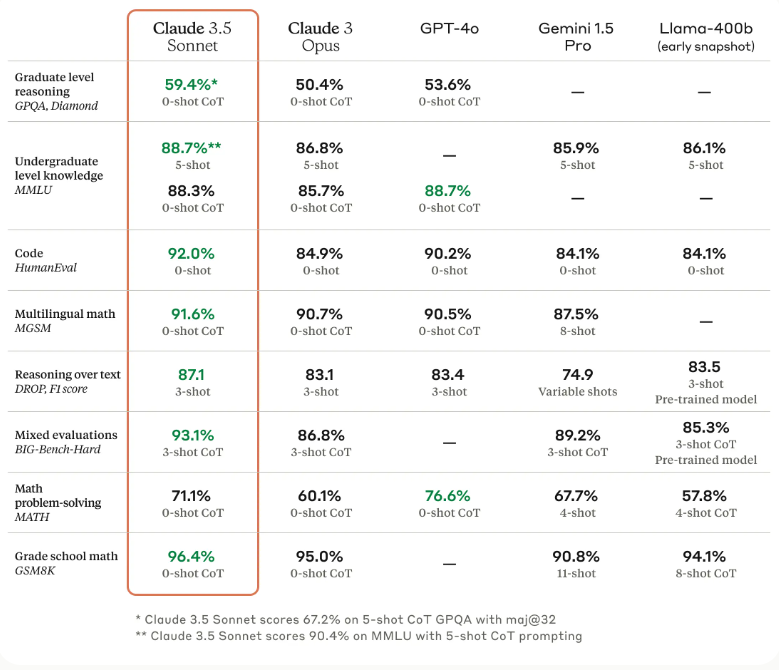
Claude 3.5 Sonnet generally outperforms GPT-4o in text-based AI benchmarks, excelling in complex reasoning and coding tasks. Its strength in nuanced problem-solving and technical proficiency positions it as a preferred choice for applications demanding detailed logical analysis and software development.
However, GPT-4.0 demonstrates significant superiority in the MMLU (Massive Multitask Language Understanding) and MATH benchmarks, where it excels in handling undergraduate-level knowledge and arithmetic problem-solving. This highlights GPT-4.0’s robustness in general knowledge and mathematical reasoning.
1. Vision performance
In terms of vision capabilities, Claude 3.5 Sonnet achieves higher scores across benchmarks such as MathVista, AI2D, Chart Q&A, and Document Visual Q&A, showcasing its proficiency in interpreting mathematical diagrams, analyzing charts, and responding to document-based queries. On the other hand, GPT-4 excels in the MMMU (Multi-modal Multi-task Understanding) benchmark, demonstrating advanced abilities in visual question answering. This makes GPT-4 particularly adept at integrating visual and textual data for comprehensive analysis.
2. Context window
Claude 3.5 Sonnet offers a substantial context window of 200K tokens, roughly equivalent to 500 pages or 150,000 words. This large context capacity allows for comprehensive data handling and more extensive interactions within a single session.
In comparison, GPT-4 provides a context window of 128K tokens, translating to approximately 90,000 words or 300 pages. While smaller, GPT-4’s context window is still significant but capped by a generation limit of 4096 tokens for output. This constraint can affect the model’s ability to produce lengthy responses or handle large-scale data in a single output.
3. Accuracy and reliability
Both models exhibit high accuracy rates. However, Claude 3.5 Sonnet’s tailored enhancements for financial modeling and technical analysis provide it with an edge in producing precise, contextually relevant outputs. This precision is crucial for industries like finance and healthcare, where accuracy and operational integrity are of utmost importance.
Which AI Model to Choose for Your Industry?
Based the comparison Claude 3.5 Sonnet emerges as the superior model for tasks involving advanced reasoning, coding, and visual data interpretation, with significant advantages in speed, efficiency, and contextual capacity. Its specialized features and enhanced accuracy in certain domains make it a top choice for applications requiring precision and high performance.
On the other hand, GPT-4 shines in general knowledge and mathematical reasoning, with notable capabilities in visual question-answering tasks. Its broader versatility and adaptability make it a valuable option for diverse use cases.
The choice between Claude 3.5 Sonnet and GPT-4 largely depends on specific operational needs. Claude 3.5 Sonnet’s strengths in financial modeling and technical analysis make it ideal for sectors requiring deep domain expertise and nuanced decision support systems. GPT-4’s broader application range is advantageous for environments where adaptable, generalized AI capabilities are required. Its versatility supports a wide range of use cases, from natural language understanding to creative content generation.
In brief
Anthropic’s Claude 3.5 Sonnet and OpenAI’s GPT-4o represent significant advancements in AI capabilities, each offering distinct advantages tailored to specific organizational needs and strategic imperatives. As AI continues to evolve, the integration of advanced models like Claude 3.5 Sonnet presents opportunities for enhanced operational efficiency and innovation across industries.