

{kind=link}
Data Mesh Architecture and Distributed Data for Nomadic DevOps and Data Teams

Today’s digital operations aren’t rooted in a single server rack or centralized cloud account—they are borderless, fluid, and increasingly autonomous. As data becomes both decentralized and mission-critical, CTOs are navigating the rise of a new architectural imperative: the distributed data layer. This evolution isn’t just technical, it’s cultural, strategic, and, for many modern enterprises, existential.
Remote DevOps teams deploy infrastructure across continents. Industrial IoT systems generate petabytes of telemetry from oil rigs, factories, and vehicles far beyond the reach of corporate clouds. Regulatory boundaries limit where and how data can move. Meanwhile, the pace of decision-making is dictated not by batch jobs but by real-time responsiveness at the edge.
Let’s explore that shift, why centralized architectures are failing, how distributed data architecture is enabling resilience at scale, and how CTOs are embracing data mesh architecture.
Data mesh architecture: The new terrain of enterprise data
Data used to be simple. You stored it, backed it up, centralized it, and built everything else around it. But in 2025, such simplicity is a liability.
Modern digital operations depend on real-time, edge-native data distributed across geographies and accessed by globally dispersed teams. This reality has made the legacy model of centralization not only obsolete but counterproductive. For CTOs, the choice is clear: adapt the architecture or risk irrelevance.
From centralization to Distribution: Why data mesh architecture is taking root
In the early 2010s, moving data to the cloud solved immediate scalability and cost challenges. It brought compute power closer to storage and enabled global access. However, as industries leaned deeper into IIoT, AI/ML, and real-time automation, cracks in the centralized model became too large to ignore.
- Latency became a bottleneck—even milliseconds mattered in operational decisions.
- Bandwidth costs soared across constrained edge networks like remote manufacturing sites or offshore oil rigs.
- Data silos and vendor lock-in reduced agility.
- Security risks increased, with centralized clouds becoming single points of failure.
The centralized model, optimized for yesterday’s problems, is now unfit for today’s realities.
What makes the distributed data layer work?
Successful adoption hinges not on the wholesale rejection of centralization, but on the creation of an intelligent, interoperable mesh. This layer is not a tool—it’s a philosophy encoded into infrastructure.
Key characteristics defining a performant distributed data layer in 2025:
1. Edge-native design
Industrial systems produce high-throughput, heterogeneous data—from SCADA logs to AI image streams. This data must be filtered, processed, and reacted to at the edge, where decisions matter most. Edge-native architectures prioritize sub-second latency and local resilience, unlocking use cases that centralized clouds cannot handle.
2. Unified namespace (UNS) for real-time contextualization
Acting as a real-time data map, the UNS unifies disparate systems under a single, dynamically updated semantic layer. It bridges MQTT brokers, legacy PLCs, modern APIs, and cloud-native databases—creating a coherent interface between IT and OT ecosystems.
3. MQTT for low-latency, bi-directional communication
As lightweight, stateful, and bandwidth-efficient protocols become essential, MQTT has emerged as the backbone for machine-to-machine communication. It supports real-time messaging across industrial deployments without incurring the cost or fragility of HTTP-based protocols.
4. Distributed query engines
Technologies like Presto, Apache Spark SQL, and Google BigQuery allow enterprises to run SQL across geographically distributed datasets without relocating them. These engines underpin data democratization by enabling analytics to follow data, not the other way around.
At its core, the Distributed Data Layer is about treating data as a dynamic, decentralized, and autonomous asset. This shift is already manifesting in industrial sectors where Operational Technology (OT) and Information Technology (IT) are converging, demanding solutions that bridge high-throughput telemetry at the edge with enterprise-scale analytics in the cloud.
Data mesh architecture and the forces driving the transition to distributed data
1. Nomadic DevOps requires a nomadic data architecture
The modern DevOps engineer isn’t tethered to a physical office, data center, or even a single cloud provider. Teams are remote, global, and fluid—so too must be the data infrastructure they rely on. The distributed data architecture supports asynchronous development and live collaboration across time zones, giving DevOps teams real-time access to telemetry, logs, and artifacts across environments.
2. AI/ML workflows are data-hungry and distribution-sensitive
Today’s AI models require massive training datasets, often pulled from geographically dispersed sensors, devices, or user interactions. Distributed query engines like Presto, Apache Spark, and Google BigQuery allow data scientists to prepare and analyze data in situ, minimizing movement and maximizing performance.
3. Data democratization is now a competitive advantage
In a world of data sovereignty, compliance mandates, and regional regulation, access—not control—is king. Distributed data models enable data democratization, empowering internal teams to access insights without centralized bottlenecks or bureaucratic handoffs.
Data mesh architecture: A blueprint for autonomy for CTOs
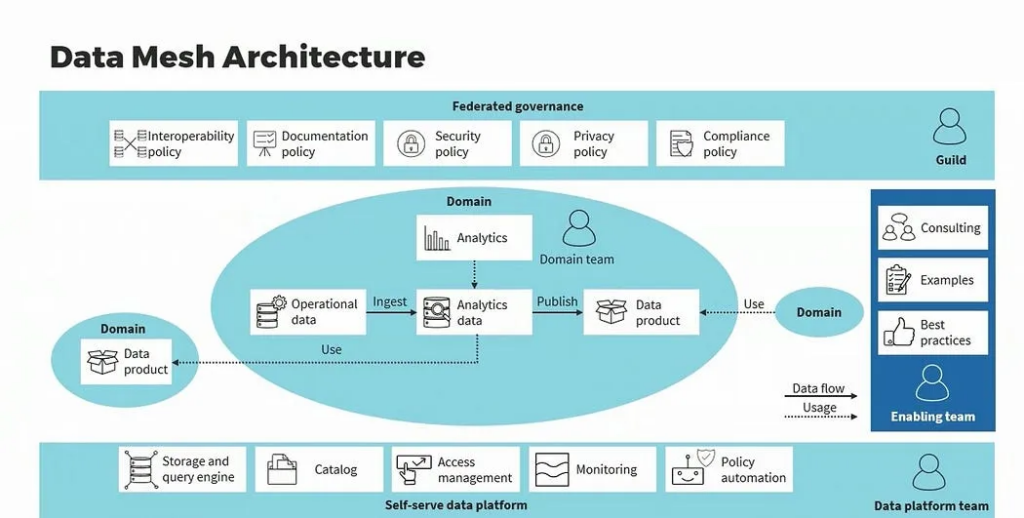
Among the most significant conceptual developments in distributed data thinking is data mesh architecture. Instead of consolidating data into massive lakes or warehouses, Data Mesh encourages domain-driven ownership, treating data as a product and decentralizing responsibility.
Core tenets of data mesh
- Domain-oriented decentralization: Data is owned and maintained by the teams that generate it.
- Self-Serve data infrastructure: Teams can access, process, and publish data without central gatekeepers.
- Federated governance: Standards are enforced across domains without reverting to centralized control.
For CTOs overseeing multi-domain organizations, Data Mesh offers an operational model aligning organizational structure with engineering autonomy.
Hybrid architectures for real-time autonomy
Real-time decisions cannot await a round-trip to the cloud in industries like manufacturing, logistics, energy, and telecom. Systems must operate autonomously—detecting anomalies, adjusting processes, or triggering alerts—all at the edge.
This requires a hybrid approach:
- Edge-native analytics for real-time responsiveness
- Distributed query engines for federated processing
- Central cloud coordination for historical analytics, model training, and orchestration
The backbone: Distributed query engines
Behind every successful distributed data strategy lies a powerful distributed query engine. Engines like Apache Hive, Presto, Spark SQL, and ClickHouse enable:
- Low-latency analytics across structured and unstructured data
- Federated querying without costly data movement
- Advanced optimization, including caching and cost-based query planning
- Scalability and fault tolerance in cloud-native or hybrid environments
More importantly, they bridge the gap between data at rest and data in motion, which is essential for predictive maintenance, demand forecasting, and adaptive supply chains.
Data mesh architecture and the Strategic imperative for CTOs
The shift toward a Distributed Data Layer transcends tools or protocols—it is a strategic rethinking of how organizations generate, access, and act on data.
Already underway:
- Retail giants are migrating from monolithic data lakes to regional mesh architectures.
- Industrial players push analytics to the edge to reduce latency and increase autonomy.
- Global tech firms empower decentralized teams with real-time access to distributed telemetry.
The future will integrate these architectures with generative AI, digital twins, and autonomous operations, extending real-time intelligence outward while maintaining coherence across the enterprise.
Strategic framework for CTOs: Architecting the distributed data layer
| Strategic Focus | Action Items | Expected Outcomes |
| Edge-Native Infrastructure | Architect data flows to support the distributed training and inference pipeline.s | Reduced latency, local autonomy, operational resilience |
| Unified Namespace Implementation | Invest in Presto, Spark SQL, or BigQuery to query data in place; avoid data movement. | Simplified data access, cross-system coherence |
| Distributed Query Engine Adoption | Enable remote access to data pipelines, telemetry, and logs; foster asynchronous collaboration. | Establish a semantic data layer bridging IT/OT systems; enable real-time data contextualization. |
| Data Mesh Governance Model | Enhanced performance, cost efficiency, and scalability | Increased agility, domain autonomy, compliance adherence |
| Support Nomadic DevOps Teams | Architect data flows to support a distributed training and inference pipeline.s | Enhanced developer productivity, reduced friction |
| Prepare for AI/ML Integration | Map data locality requirements; ensurethe distributed architecture respects legal constraints | Accelerated AI readiness, better model accuracy |
| Compliance and Sovereignty | Increased agility, domain autonomy, and compliance adherence | Risk mitigation, global regulatory compliance |
Data mesh in practice: Real-time, edge-native, and federated
For CTOs overseeing large, multi-domain organizations, Data Mesh offers an operational model that aligns with both organizational structure and engineering autonomy.
In industries like manufacturing, logistics, energy, and telecom, real-time decision-making cannot wait on a roundtrip to the cloud. Systems must operate autonomously, detecting anomalies, adjusting processes, or triggering alerts, all at the edge.
This demands a hybrid model:
- Edge-native analytics for real-time responsiveness
- Distributed query engines for federated processing
- Central cloud coordination for historical analytics, model training, and orchestration
More importantly, they bridge the gap between data-at-rest and data-in-motion, which is key for applications like predictive maintenance, demand forecasting, and adaptive supply chains.
The shift toward a distributed data layer is not about the latest tool or protocol. It is a strategic rethinking of how organizations generate, access, and act on data.
For the modern CTO, this evolution is not optional. It’s already happening:
- Retail giants are shifting from monolithic data lakes to regional mesh architectures.
- Industrial players are pushing analytics to the edge to reduce latency and increase autonomy.
- Global tech firms are empowering decentralized teams with real-time access to distributed telemetry.
In brief
The distributed data layer is more than an architecture; it’s a philosophy. It demands letting go of control in favor of enablement. It prioritizes velocity over central oversight. And it recognizes that in a world defined by movement, data must move with us, or better yet, be where we already are. For those building the future, the question is no longer if you’ll embrace distributed data, but how fast you can do it.



