

{kind=link}
AI Voice Agents Beyond Transcripts: Rethinking Enterprise AI Listening with ELM
For years, enterprise AI has been built on a simple assumption that if machines can read language, they can understand people.
That assumption is now being challenged.
As AI moves into real-world environments, the limitations of text-first systems are becoming increasingly clear. Human communication is not just words. It is tone, pauses, emotion, and intent. These signals are often lost when a voice is reduced to a transcript.
Mike Pappas, CEO and Co-Founder of Modulate, shares how the Company is rethinking AI systems to move beyond transcription and toward true listening.
A new AI architecture: Ensemble listening models
Modulate announced a fundamentally new AI architecture called the Ensemble Listening Model, or ELM. This represents a departure from LLM-based approaches that flatten voice into text, thereby missing critical context such as emotion, timing, and intent.
ELMs coordinate up to 100 specialized models in real time to analyze conversations as multidimensional signals. This is not just a product enhancement but a shift in how AI systems are designed for enterprise use.
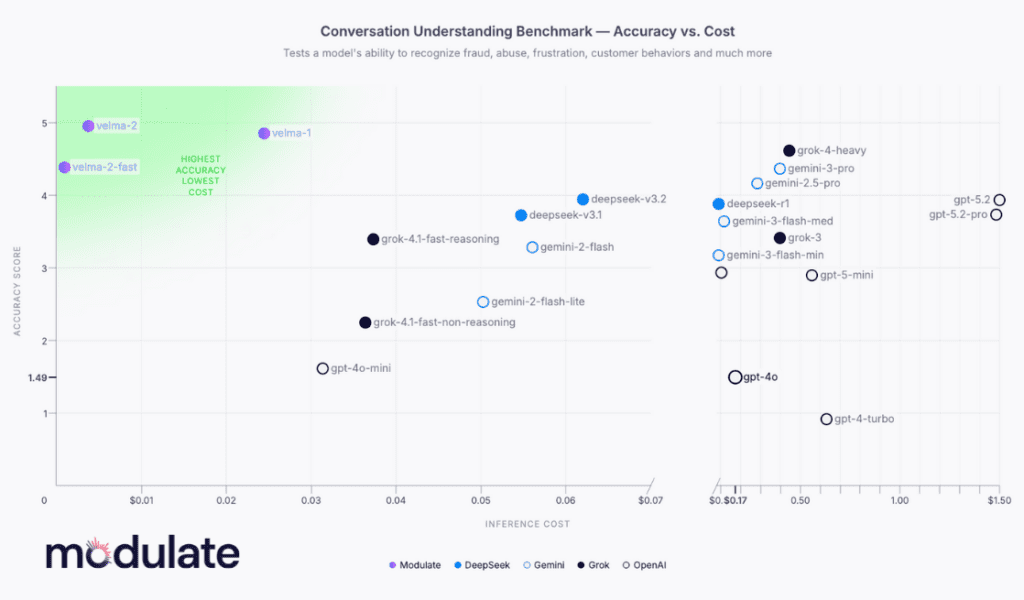
Velma 2.0: Proven at enterprise scale
At the center of this architecture is Velma 2.0, Modulate’s voice-understanding ELM, which is already in production.
It powers hundreds of millions of conversations across Fortune 500 companies and major platforms such as Call of Duty and Grand Theft Auto Online. Unlike traditional systems, Velma 2.0 interprets not just words but also emotion, prosody, timbre, and behavioral context.
The result is higher accuracy, significantly lower cost, and more transparent outputs, addressing common enterprise AI challenges such as hallucinations and lack of explainability.
Industry leaders such as Jensen Huang have pointed toward coordinated multi-model systems as the next major shift in AI, and ELM demonstrates what that looks like in practice.
In conversation with Mike Pappas
To start, I’d love to learn more about your journey. How did it all begin for you, and how did Modulate come into the picture?
Mike Pappas:
Sure. So Modulate is a voice AI company that traces its roots back to my time as an undergraduate. I was a physics student at MIT walking down a hall and saw someone working on an interesting-looking physics problem at a whiteboard. So I mustered up all of my social courage and stood awkwardly behind him for a few minutes until I found the missing minus sign to solve the equation.
Subscribe to our bi-weekly newsletter
Get the latest trends, insights, and strategies delivered straight to your inbox.
That turned out to be Carter, who is now my co-founder and CTO. So we’ve known each other for a long time. And like many college kids, we had this idea that we should start a company and go change the world. But we took it a little further than most and actually prototyped a lot of different startup ideas through our time in college to try and understand what it means to do market research. What does it mean to actually deliver a product that people can use?
Didn’t find anything we were truly excited about in college, but we knew we wanted to do something about how people interact online. So we went off and got jobs in the real world, trying to hone our skills.
Cut to a few years later, and Carter reaches out to me. He’s been playing with AI and has developed some of the first models that Modulate used for voice processing. And so he’s reaching out to me and saying, hey, I think there’s something to understanding voice with AI. Maybe there’s an opportunity there. It resonated, we jumped in, and from there the company has just sort of grown.

When you look at how AI systems handle voice today, most of it still revolves around transcription. At what point did you realize that this approach was fundamentally missing something?
Mike Pappas:
Yeah, so when people think about AI listening to what we say, they immediately assume, well, we’ll just transcribe the audio. And that is the necessary way to use LLMs. LLMs are text-based models, so you have to transcribe the audio and then feed the text through the LLMs.
The gap that we saw is that that’s not how human beings work. You know, transcripts are only one part of this conversation that we’re having. The emotion, the pauses, even the timbre of my voice tell you really meaningful things. And especially in an enterprise application or a social safety application, the devil is really in the details, and you’re not going to be able to accurately understand the interaction if you don’t understand those hidden nuances of voice.
So that was sort of our excitement is saying we don’t need to rebuild the brains, so to speak, of these LLMs. We need to give them better ears so that they can actually understand human beings the way we like to communicate with each other.
There’s also a cost and scalability angle here. At what point did that start influencing how you were thinking about building these systems?
Mike Pappas:
Suddenly, there are very few companies in the world that can afford that annual invoice. So that created an extra level of pressure for us to really think about how to shed all of the extra stuff you don’t need and just build an AI system that is laser-focused on the intelligence you need it to have.
And that again led to this ELM design.
And when we talk about industries like gaming, what were some of the hardest technical challenges in analyzing real-time conversations?
Mike Pappas:
I think the biggest challenge in gaming is how thin the line can be between acceptable conversations and unacceptable ones.
Gamers love to trash-talk. They love to rag on each other. It is part of the experience, and you want them to have a good time.
When we first started, most moderation systems were just saying things like the F word is bad, never say it. But among adult friends, that word is fairly common, especially in a gaming context, and it can be used positively or negatively. You need to understand that context.
Then you get into more subtle situations where people may throw pretty harsh insults at their friends, but there is an understanding between them. The same line said to a stranger can cause real harm.
So you have to understand not just what is being said or even the emotion behind it, but how it is being received, what the relationship is between participants, and what the broader context is.
We often say gaming is hard mode because all these signals are so close to each other. Because we started there, we were forced to solve the hardest version of the problem. That gave us a much richer dataset. So now, when we move into industries like FinTech, we are solving that last 10 percent problem, which is often where the real risk lies.
So how do you actually differentiate between sarcasm, banter, and genuine abuse in voice interactions?
Mike Pappas:
It is ultimately an AI system. We have trained on a very large amount of conversational data, over half a billion hours across enterprise, social, and gaming use cases.
That allows us to make these systems very strong. Each component model is highly specialized. Our transcription model is extremely strong at noisy speech. Also, our deepfake detection model is highly effective at catching adversarial synthetic voices. Our emotion and interruption models are also highly refined.
At a certain point, it comes down to exposure. Humans can detect sarcasm because we have heard it enough times. AI can do the same if it is actually listening to the audio and has the data to learn from.
Do you see this as a shift beyond LLMs entirely, or do you think ELMs and LLMs will coexist?
Mike Pappas:
I think it is the latter. ELMs will allow us to deploy AI into environments where LLMs were not the right solution, whether that is because they are black boxes, too costly, or too difficult to train.
LLMs are still incredibly powerful, and they will continue to be widely used. But many enterprises have realized that they are not always the right tool for the problems they face. So I think we will continue to see LLMs used heavily, especially in the consumer space, while new architectures like ELM become more prominent in enterprise use cases.
Looking ahead five years from now, what are the trends or use cases you are most excited about when it comes to ELMs?
Mike Pappas:
It is a great question. I think what I am most excited about is the range of applications ELMs will be used for. They are designed to handle multimodal data. Audio is one example, where there is both content and delivery, such as tone and prosody.
Another example is self-driving cars, where you have the sensor fusion problem and need to combine multiple data streams. ELMs are well suited for that. There are also challenges with LLMs around long memory and context. ELMs can approach that differently. For example, in long meetings, they can model different participants separately and build a richer understanding.
So I am really excited to see how this concept expands beyond voice. That is where we started, but it is not the only use case. There is a lot more opportunity for people to build on this approach.
To explore more expert perspectives on AI voice agents, enterprise AI architecture, and emerging technologies shaping real-world applications, explore here!
