

{kind=link}
Why Global Data Synchronization Is the Backbone of AI-Driven Enterprises
AI thrives on one thing: fresh, consistent, and complete data. But most enterprises today are juggling fragmented architectures, legacy ERP systems in one region, SaaS analytics in another, and new cloud data lakes running somewhere in between.
When each region or business unit operates with slightly different versions of data, the result is predictable chaos.
AI models trained on inconsistent information deliver inconsistent outcomes. Customer insights become unreliable. Compliance audits become nightmares.
Global data synchronization ensures that every system, from CRM to analytics platform to AI engine, works from the same, up-to-date version of truth. It connects data across borders and business functions, turning fragmented silos into a unified data fabric.
It’s not glamorous. But it’s essential.
From batch to real-time: The shift that defines AI readiness
There was a time when nightly batch jobs were enough.
Data would move once a day, feeding dashboards and reports the next morning. However, by 2025, that will be ancient history.
Modern AI systems demand real-time synchronization, where updates flow continuously, not periodically. Whether it’s a retail AI predicting demand shifts or a global bank preventing fraud, milliseconds matter.
Batch synchronization still works for static reporting—but not for global enterprises managing live transactions, IoT feeds, or generative AI models.
Global data synchronization and the real-time advantage
Real-time synchronization turns data pipelines into data streams.
Subscribe to our bi-weekly newsletter
Get the latest trends, insights, and strategies delivered straight to your inbox.
- Immediate decision-making: AI models and analytics tools work on what’s happening now.
- Fewer sync failures: No more stale data or version mismatches.
- Faster insights: Teams move from “reporting what happened” to “responding as it happens.”
Understanding the core types of data synchronization
Global synchronization isn’t one-size-fits-all. The right method depends on latency tolerance, data complexity, and operational needs.
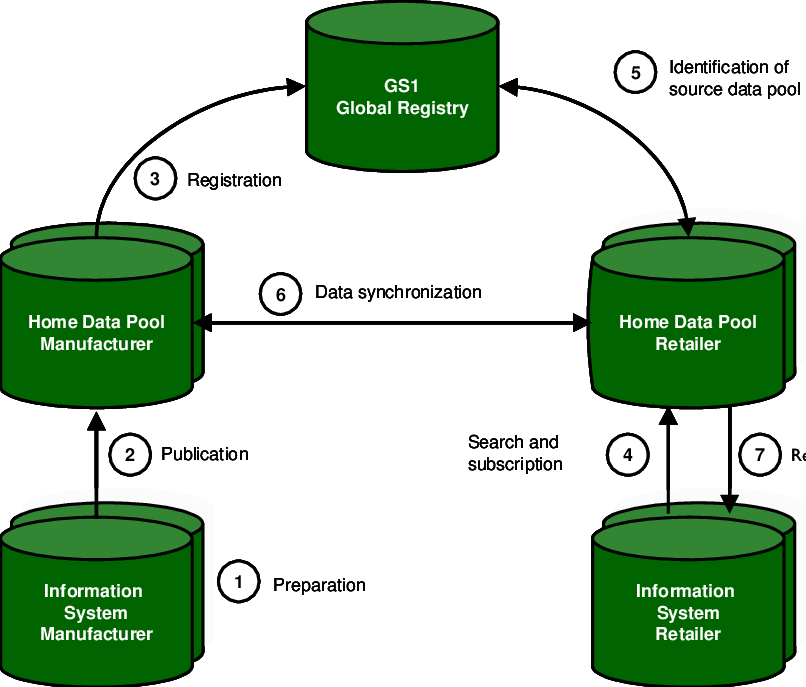
[Image Source: Researchgate]
One-way vs. two-way synchronization
- One-Way Sync: Data flows from a single source to many destinations, common for analytics workloads.
- Two-Way Sync: Systems update each other, crucial for collaborative or distributed operations.
Full vs. incremental synchronization
- Full Sync copies everything, a brute-force but inefficient method.
- Incremental Sync, powered by Change Data Capture (CDC), only moves what’s changed, in real time.
Real-time vs. batch
- Batch Sync: Periodic, high-latency updates.
- Real-Time Sync: Instant updates across global systems, essential for AI and live analytics.
The hidden cost of unsynchronized data
When data isn’t synchronized globally, the consequences ripple across the enterprise.
- AI Drift: Machine learning models degrade quickly when trained on outdated or inconsistent data.
- Customer Friction: Out-of-sync CRMs and support tools mean customers get irrelevant messages or repeated errors.
- Compliance Risk: Without a traceable, unified data lineage, meeting audit and regulatory requirements becomes near impossible.
- Operational Inefficiency: Teams waste hours reconciling mismatched datasets instead of driving innovation.
In essence, poor synchronization creates invisible drag on every part of the business.
How global data synchronization works behind the scenes
At its core, synchronization is about moving data efficiently, securely, and accurately between systems. Modern synchronization architectures typically involve three main stages:
Step 1: Capturing changes in real time
This starts with Change Data Capture (CDC). Instead of constantly querying databases, the CDC listens to transaction logs and captures every insert, update, or delete as they happen.
It’s the most efficient way to detect change—low overhead, minimal lag, and zero impact on production workloads.
Step 2: Processing data in motion
Once data is captured, it flows through real-time processing layers where it can be cleaned, transformed, and enriched.
Platforms like Striim, Fivetran, Informatica, IBM DataStage, etc, enable teams to apply SQL-based transformations in-flight, reducing complexity and ensuring that every downstream system receives consistent, high-quality data.
Step 3: Delivering data across destinations
Finally, the processed data is streamed to multiple destinations simultaneously, whether that’s Snowflake, BigQuery, Databricks, Salesforce, or Kafka.
The goal: create a “read once, deliver everywhere” pipeline that keeps global systems aligned without duplication or latency.
Key Challenges in achieving global data synchronization
Despite its importance, achieving reliable global synchronization remains one of the toughest technical challenges for enterprises.
1. Multi-cloud and hybrid fragmentation
Most enterprises run a patchwork of legacy on-prem systems and new cloud applications. Synchronizing data across these environments introduces latency, data silos, and integration complexity.
2. Latency and bandwidth constraints
When operations span multiple continents, network delays can affect sync performance. AI models trained in one region may not reflect real-time updates from another.
3. Schema drift and data evolution
As applications evolve, data structures change. Without intelligent schema detection and evolution handling, pipelines break silently.
4. Security and compliance
Global data movement introduces regulatory friction. Data sovereignty laws (like GDPR and CCPA) demand complete visibility into where and how data travels.
5. Observability and monitoring gaps
Legacy pipelines lack real-time observability. When syncs fail or lag, teams often discover the issue hours later, after the damage is already done.
Best Practices for CTOs for scalable, reliable global data synchronization
To transition from reactive fixes to proactive resilience, enterprises must rethink synchronization as a core architectural capability, rather than a backend afterthought.
1. Build for change
Design pipelines that anticipate schema drift, evolving endpoints, and scaling workloads. Use platforms with automated health checks, alerts, and self-healing mechanisms.
2. Prioritize real-time from the start
AI and analytics initiatives only deliver value when data is fresh. Real-time pipelines powered by CDC and event-driven architecture are no longer optional; they’re table stakes.
3. Focus on reusability
Avoid point-to-point integrations. Build modular, reusable pipelines that can easily support new data sources and targets as your stack evolves.
4. Bake in governance and observability
Embed encryption, audit trails, and role-based access controls directly into the synchronization layer. This ensures compliance without slowing down operations.
5. Align with business outcomes
Tie synchronization KPIs to business metrics, customer satisfaction, decision latency, fraud prevention rates, so the data team’s impact is measurable.
Use Cases: Where global synchronization delivers impact
Real-time AI and machine learning
Continuous synchronization ensures that AI models remain accurate and responsive.
Predictive analytics, recommendation engines, and fraud detection all rely on live data streams.
Personalized customer experience
Unified data across geographies ensures every interaction feels tailored and timely, no more sending offers for products already purchased.
Supply chain and inventory optimization
Real-time synchronization gives a live view of global inventory as well as supplier data, enabling proactive decision-making.
Compliance and risk management
Synchronization ensures that compliance reports and audit trails are consistent worldwide, reducing regulatory exposure.
Choosing the right global data synchronization platform
When evaluating synchronization tools, CTOs should look beyond speed. The right platform should offer:
- Real-time CDC-based synchronization for sub-second latency.
- Broad connector support across databases, clouds, and SaaS tools.
- Built-in transformations for on-the-fly data shaping.
- Enterprise-grade governance with full observability.
- No-code/low-code flexibility to empower more teams.
- Proven scalability for global, mission-critical workloads.
| Feature / Capability | Importance for CTOs | Key Considerations | Example Benefit |
|---|---|---|---|
| Real-Time Sync | High | Sub-second latency, support for Change Data Capture (CDC) | Enables AI and analytics to operate on live data, reducing decision delays |
| Scalability | High | Handles multi-region, multi-cloud, and high data volumes | Supports enterprise growth without re-architecting pipelines |
| Interoperability | Medium-High | Compatibility with ERP, CRM, analytics, and operational systems | Reduces integration costs and avoids siloed data |
| Cloud & Hybrid Support | High | Works across on-premise, cloud, and hybrid infrastructures | Seamlessly connects legacy systems to modern AI platforms |
| Security & Compliance | Critical | Role-based access, encryption, audit logs, GDPR/CCPA compliance | Minimizes regulatory risks and data exposure |
| Low-Code / No-Code Interface | Medium | Ease of adoption across teams beyond IT | Faster implementation and broader organizational buy-in |
| Observability & Monitoring | High | Alerts for sync failures, schema drift, and performance issues | Proactive issue detection and resolution, reducing downtime |
| ROI / Cost Efficiency | High | Measures time saved, error reduction, and operational efficiency | Ensures investment delivers tangible business value |
| Vendor Support & SLAs | Medium | 24/7 support, uptime guarantees, documentation | Provides reliability and mitigates operational risks |
Platforms like Striim exemplify this modern approach, offering unified, low-latency synchronization that powers AI, analytics, and operations at an enterprise scale.
In brief
Global data synchronization may not grab headlines, but it’s the invisible force keeping the AI economy running. As organizations race to scale their intelligent systems, those who master real-time, unified data movement will be the ones that lead, not follow, the next wave of innovation.
_____________________________________________________________________________________________
FAQs
1. What is global data synchronization?
It’s the process of keeping data consistent and up-to-date across multiple systems, regions, and clouds in real-time, ensuring that all business units operate on the same source of truth.
2. Why is real-time synchronization important for AI?
AI models need the freshest possible data to make accurate predictions. Real-time synchronization provides continuous updates, preventing “model drift” and enhancing decision quality.
3. How is global data synchronization different from ETL?
ETL focuses on batch extraction and transformation for analytics, whereas synchronization involves the continuous, real-time movement and alignment of operational data.
4. What are the biggest challenges in global synchronization?
Cross-region latency, data security regulations, schema drift, and observability are among the top concerns for enterprise teams.
5. What tools support global data synchronization at scale?
Platforms like Striim, Fivetran, and Informatica offer enterprise-ready solutions, but Striim stands out for its CDC-based, low-latency, multi-cloud streaming capabilities.